
Непредвиденное поведение компилятора
В предыдущем разделе в своих ошибках мы подозревали поставщика компилятора, но он оказался не виноват. К сожалению, это не всегда так и, поскольку у разработчика обычно нет доступа к исходному коду компилятора, выявить ошибки компилятора очень трудно.
Много лет назад у нас был компилятор, который регулярно выдавал сообщения о синтаксических ошибках на неверных строках исходного кода. Это не было такой уж серьёзной неприятностью, поскольку поиск в обратном направлении от того места, где компилятор сообщал об ошибке, всегда позволял определить строку, где ошибка была допущена на самом деле. В некоторых случаях ошибка определялась на нужной строке; иногда погрешность составляла 10 строк или больше. По мере написания проекта и увеличения размера файлов, проблема, казалось, прогрессировала. Так же мы выяснили, что на наш отладчик влияло наличие несинхронных строк. Когда мы стали отлаживать код, отмеченная исходная строка отличалась от той, которая выполнялась. Это было намного серьезнее, чем передача неверного расположения синтаксических ошибок, так как теперь в некоторых случаях было невозможно установить путь выполнения кода.
Поставщик компилятора уверил нас, что строки были асинхронны из-за оптимизации, которая устранила или сократила некоторые из наших путей выполнения. Это, возможно, было вероятным объяснением проблемы в отладчике, но этим не объяснить неверно передаваемое расположение синтаксической ошибки.
И снова перед нами макрос __LINE__. В некоторых случаях, подобно макросу assert(), макрос __LINE__ используется прикладным программистом, чтобы сообщить о расположении событий во время выполнения кода. Однако компилятор может также использовать этот макрос для целей своего внутреннего обслуживания. Значение __LINE__ может быть изменено директивой #line. Фактически, если Вам не нравится способ, которым компилятор нумерует строки в файле, Вы можете изменить нумерацию строк:
#line 2000
Напишите эту строчку в код Вашего коллеги перед тем, как он начнет его компилировать, и вы получите удовольствие, потому что уведомление обо всех синтаксических ошибках будет размещено не на тех строках.
Код, который сгенерирован компилятором, может использовать директивы #line, чтобы сохранить нумерацию строк в сгенерированном файле синхронизированным с кодом первоисточника. Этот метод был распространен в компиляторах C++, которые генерировали код C. Код C включал директиву #line в начале блока кода, который представлял одну строку C++. Как правило, файл C был намного больше, чем исходный файл C++, но директива #line означала, что номер сообщаемой строки указывал пользователю на корректное местоположение в исходном источнике C++.
Подобный метод используется препроцессором C. Препроцессор разворачивает все макросы, удаляет все комментарии и вставляет содержание любых файлов, которые определены директивой #include. Результат этих шагов сохраняется в едином файле, который затем передается компилятору.
Конечно, этот единственный файл намного больше, чем исходный файл, так как может содержать много включенных файлов. Выходной файл препроцессора - это обычно временный файл, который пользователь никогда, обычно не видит, но большинство компиляторов имеют опцию сохранения этого файла, если он Вам нужен для исследования. Вот что я сделал, чтобы узнать, почему номера строк всегда были ошибочными. В Листинге 2 показаны два небольших файла и результат, сгенерированный препроцессором. В пределах каждого заголовочного файла используется директива #line, чтобы указать на строку и имя файла, о котором нужно сообщить при возникновении ошибки.
header.h
// This is a header
typedef int B;
c.c
// This is a C file
// with one function
#include "header.h"
void foo(void)
{
// do nothing
}
Output of cpp run on c.c
#line 1 "c.c"
#line 4 "header.h"
typedef int B;
#line 4 "c.c"
void foo(void)
{
}
Листинг 2. Два небольших файла и результат, сгенерированные препроцессором
Например, если была ошибка в определении типа заголовочного файла .h (header.h) директива #line сообщает компилятору, что текущей строкой, с точки зрения пользователя, является Строка 4. Директива #line берет дополнительный второй параметр, который определяет имя файла. Этот шаг необходим чтобы мы могли отличить заголовочные файлы друг от друга и от файла C после того, как они все были объединены препроцессором.
Проблема, обнаруженная при исследовании этого файла, состоит в том, что директива #line после заголовочного файла указывает, что следующая строка должна быть Строкой 4, когда фактически следующая строка - пятая строка в исходном файле. После этой точки весь источник не согласуется с разницей в одну строку. Если мы включаем другой заголовочный файл, ошибка увеличивается до двух строк. Некоторые заголовочные файлы имели такое влияние, а другие нет. В конечном счете, различие между заголовочными файлами было точно определено как проблема с последней строкой файлов. Редактор, которым мы пользовались, позволяет нам включать заключительную строку в файле, в котором нет возврата каретки. Версия поставщика препроцессора не увеличивала счетчик строк, если не было возврата каретки. Чтобы отследить номера строки правильно, последняя строка в файле должна сопровождаться возвратом каретки, за которой следует маркер конца файла. Многие редакторы имеют такую функцию, поэтому некоторые пользователи никогда не подвергались этой ошибке. Наш редактор, CodeWright, позволяет заключительной строке заканчиваться без возврата каретки, поэтому нас застали врасплох.
Мы не смогли убедить поставщика компилятора, что этот дефект стоит исправить. Некоторые версии препроцессора не допускают строку без возврата каретки, но они сообщают этом как об ошибке, что намного более приемлемо, поскольку Вы сразу видите источник проблемы. Нам пришлось вручную проверять все наши заголовочные файлы, чтобы убедиться, что последняя строка всегда сопровождается возвратом каретки, и все наши проблемы с синхронизацией строк ушли.
Начальные условия и переходы
Иногда чтение входного сигнала может вызвать ошибки, если не рассматривается его начальное состояние. В одном проекте у нас была схема, в которой напряжение батареи сравнилось с опорным напряжением. Для этих целей использовался компаратор, выходной сигнал с которого, подавался на специальных вход микроконтроллера, где он защелкивался в регистре, пока программа не сбрасывала его. Защелка срабатывала по заднему фронту сигнала. Сигнал назывался BATT_LOW.
Сигнал компаратора можно было соединить с прерыванием, что входило в наш первоначальный замысел. Но поскольку напряжение батареи падает медленно и быстрой реакции не требуется, мы выбрали метод регулярного опроса. Ошибка, которую я собираюсь описать, может произойти и при использовании прерывания, и при опросе.
Когда система работала от батареи, программное обеспечение опрашивало бит BATT_LOW и отключало систему, если он был установлен в 1. Также система могла работать от сети, и в этом случае сигнал BATT_LOW игнорировался.
Мы обнаружили, что были случаи, когда при переключении питания с электросети на батареи, система работала на более низком уровне напряжения, хотя сигнал BATT_LOW при этом должен был переключиться и вызвать отключение устройства. Работа при таком низком уровне заряда могла заставить систему вести себя непредсказуемым способом.
Наблюдая за битом BATT_LOW, мы поняли, что в сбойных случаях он просто не устанавливался в 1. Проблема состояла в том, что если заряд батареи был низким и мы начинали работать от сети, входная схема не могла перейти в низкое состояние, поскольку уже была в нем, и защелка, фиксирующая фронт, не срабатывала. Не было фронта, и, соответственно, никакой индикации того, что заряд батареи низкий.
У этой ошибки было две причины. Использование фронта сигнала было не подходящим решением. Когда мы решили не использовать прерывание, нужно было изменить схему чтобы детектировать состояние батареи, вместо того, чтобы использовать сигнал, который фиксировал переход из одного состояния в другое. Вторая проблема состояла в том, что мы не рассматривали начальное состояние сигнала, который собирались фиксировать. Мы неразумно предполагали, что всегда будем начинать работать на хорошо заряженной батарее, так как при низком заряде устройство не запуститься. Но в итоге получилось, что если мы переключаем питание от электросети на слабую батарею, возникает ситуация, когда входной сигнал в низком состоянии и не может перейти от высокого к низкому уровню. А если нет перехода, то BATT_LOW никогда не устанавливается, так как этот бит устанавливался фронтом.
Несинхронизируемые счетчики
Программисты любят помещать константы в #define`ы или в объявления const. Это позволяет им легко менять значения позже, при этом не возникает ощущение, что код или алгоритм действительно поменялся. Однако важно понимать, что изменение значения может иметь более сильный эффект, чем требуется.
У нас была система, которая использовала задержки, для ожидания стабилизации определенных параметров. Одному из параметров системы требовалась трехминутная задержка. Поскольку у нас был счетчик, который постепенно увеличивался каждую минуту, мы определили значение через именованную константу WARMUP_DELAY равную 3. В начале задержки мы записывали значение минутного счетчика как DelayStart. Как только минутный счетчик достигал значения DelayStart + WARMUP_DELAY, задержка завершалась.
Счетчик обновлялся раз в минуту, таким образом, у нашего измерения времени было одноминутное разрешение. Запуск нашей задержки не был синхронизирован с этими обновлениями, поэтому фактическая задержка составляла от двух до трех минут, как показано на рисунке. Но это не было проблемой, поскольку точная продолжительность задержки не была важна. По сути, пока задержка длилась более 20 секунд, все работало нормально.
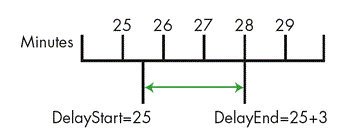
Рисунок 1. Задержка на три фактически длится от двух до трех минут.
Позднее мы пытались уменьшить в проекте время, в течении которого система ожидала стабилизации параметров. Три минуты были слишком длительным временем для задержки WARMUP_DELAY, и я с радостью уменьшил ее до одной. В то время, я не подумал, что значение 1 в действительности означало время, меньше одной минуты или равное ей. И в некоторых случаях задержка составляла меньше 20 секунд, что приводило к нарушению работы системы. Время задержки изменялось в зависимости от того, насколько близко запуск задержки находился по отношению к точке обновления минутного счетчика. Таким образом, проблема иногда возникала, а иногда нет, усложняя ее поиск.
Мораль этой истории в том, что разрешение и контекст использования нужно рассматривать всякий раз, когда изменяются константы. Обнаружив свою ошибку, я понял, что эта проблема счетчиков, обеспечивающих таймеры ограниченной точности, та же самая, с которой вы столкнётесь, если будете использовать таймеры предоставляемые RTOS или счетчик, который постепенно увеличивается в прерывании. Обычно такие таймеры имеют миллисекундный интервал, а не минутный, но принцип тот же самый: если счетчик используется для измерения времени, и задержка запущена не синхронно с обновлением счетчика, она может быть неточной до одного тика счетчика.
Аппаратные факторы
Заключительный пример относится к моим любимым, потому что он демонстрирует, как легко планировать программное обеспечение, не уделяя достаточного внимания взаимодействию устройства с физическим миром. Это как раз те вопросы, благодаря которым ПО для встраиваемых систем становится более интересным, чем эквивалентное программное обеспечение для компьютера.
В качестве способа экономии электроэнергии на одном медицинском аппарате использовался "тусклый" режим, при котором уменьшалась интенсивность всех светодиодов и подсветок на передней панели. Поскольку устройство часто использовалось ночью в больничных палатах, тусклый режим был предназначен для увеличения времени работы от батареи, а также для уменьшения дискомфорта пациентам, которые спали в палате с выключенным светом. Замысел состоял в том, что, когда уровень света был низким, программное обеспечение включало тусклый режим. Утром, когда поднималось солнце, или был включен свет, передняя панель светилась с нормальной интенсивностью. Для анализа уровня освещенности использовался фототранзистор, помещенный напротив небольшого отверстия на передней панели.
На деле мы обнаружили, что устройство часто переходило в тусклый режим в неподходящее время и оно не было случайным. Оказалось, что это происходит, когда пользователь взаимодействует с устройством, а не время от времени, когда устройство неактивно. В ходе небольших наблюдений удалось установить причину. Отверстие, где находился фототранзистор, располагалось у середины передней панели. Всякий раз, когда праворукий пользователь помещал руку на кнопку слева от отверстия, оно попадало в тень от руки, и устройство «думало», что наступала ночь. Даже при том, что у сигнала был устранён «дребезг», этого было недостаточно, чтобы различить тень, отброшенную рукой человека на несколько секунд, что происходило, когда пациенты нажимали на кнопки слева от датчика.
Решение было простым: мы значительно увеличили время обработки дребезга. Также мы игнорировали любые переходы в сигнале, которые имели место в течение нескольких секунд после нажатия клавиши. В идеальном варианте, мы изменили бы и расположение датчика, но к тому времени, когда мы обнаружили эту проблему, аппаратные средства были уже на поздней стадии разработки, и более прагматичным решением было изменение программного обеспечения.
Все ошибки, описанные выше, повторяются в различных проектах, написанных разными программистами. Понимание ошибок, с которыми вы встречались ранее, будь они ваши собственные или ваших коллег, или же вы о них просто читали, поможет вам диагностировать новые ошибки. Счастливого «выдирания» багов.
Как избежать типичных багов встроенного ПО. ч.1
Niall Murphy "How to Avoid Common Firmware Bugs"
Вольный перевод ChipEnable.Ru
Comments
Как правило большинство придумок не работает в протеусе, а даже то что работает в протеусе, нельзя назвать рабочим в железе. Последняя инстанция макетка или готовое устройство.
RSS feed for comments to this post