
4. Советы и трюки по уменьшению времени выполнения кода
В этом разделе мы рассмотрим советы по уменьшению времени выполнения кода. Для каждого совета будет дано описание и пример.
4.1 Совет #8 - размеры и типы данных
Правильный выбор типа данных уменьшает не только размер кода, но и время его выполнения. Для 8-и битных AVR использование однобайтных значений – это наиболее эффективный путь.
Таблица 4-1. Пример использования различных типов данных.
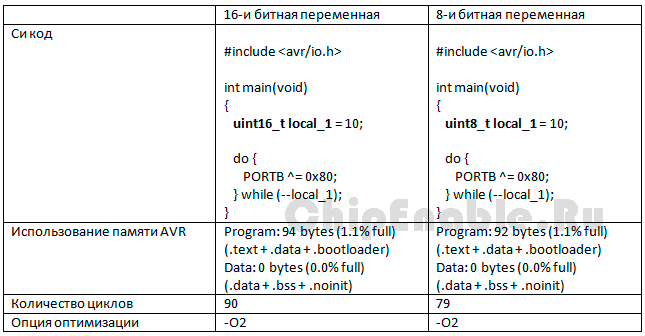
Обратите внимание, что при оптимизации -O3 цикл автоматически развернется компилятором в повторяющиеся операции и разницы между примерами не будет.
4.2 Совет #9 – условный оператор
Обычно между предекрементом и постдекрементом (или преинкрементом и постинкрементом) нет никакой разницы, если эти операторы используются отдельно. Например “i- -;“ и “- -i;” преобразуются компилятором в одинаковый ассемблерный код. Однако если эти операторы используются в составе циклов или условных операторов, то сгенерированный код будет разным.
Как говорилось в совете #3, использование в цикле декремента индексной переменной уменьшает размер кода. Это также помогает получить более быстрый код и в условных операторах.
Кроме того, предекремент и постдекремент дают разные результаты. Из примера в таблице 4-2 мы можем видеть, что более быстрый код получается при использовании в условном оператора предекремента. Значение счетчика циклов здесь представляет время выполнения длиннейшей итерации цикла.
Таблица 4-2. Пример условного оператора
Переменной “loop_cnt” присваиваются разные значение, но поведение программы будет одинаковым: PORTC переключается 9 раз, а PORTB за это время 1 раз.
4.3 Совет #10 – развертывание циклов
В некоторых случаях, для увеличения быстродействия кода, мы можем разворачивать циклы. Это особенно эффективно, если они короткие. Когда цикл развернут, отпадает потребность в индексной переменной и ее проверках при каждой итерации.
В таблице 4-3 показан пример, где мы инвертируем один вывод порта 7 раз.
Таблица 4-3. Развертывание циклов.
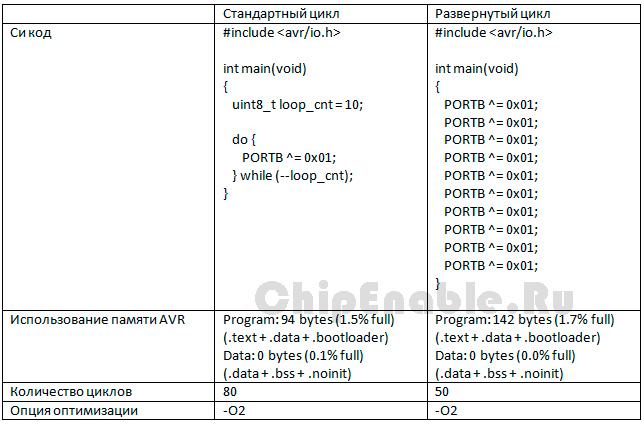
Заменив цикл последовательностью операций, мы увеличили скорость выполнения кода с 80 циклов до 50. Однако имейте в виду, код в этом случае увеличится с 94 байтов до 140.
Также следует заметить, если для левого примера включить оптимизацию –O3, компилятор развернет цикл автоматически.
4.4 Совет #11 – управление потоком: if-else и switch-case
“If-else” и”switch-case” широко используется в Си и правильная организация ветвлений может увеличить быстродействие кода.
Для “if-else” размещайте наиболее вероятное условие на первое место. Тогда следующие условия будут выполняться реже и среднее время выполнения кода уменьшится.
Используя “switch-case” можно устранить недостатки “if-else”, потому что для “switch-case” компилятор обычно создает таблицу перекодировки с индексами и переходит на нужную ветвь напрямую (без последовательного перебора).
Если использовать “switch-case” сложно, мы можем разделить “if-else” ветви на более мелкие подветви. Этот метод снижает время выполнения кода для наихудшего случая. В примере ниже, мы получаем данные с АЦП и затем передаем их с помощью USART. “ad_result <= 240” – это наихудший случай.
Таблица 4-4. Пример использования “if-else” подветвей

Как мы видим, такой подход позволяет сократить время, которое требуется для достижения самой отдаленной ветви условного оператора. Однако размер кода у нас при этом увеличился. В таких случаях приходится искать баланс между объемом кода и скоростью его выполнения, исходя из требований решаемой задачи.
5. Пример проекта и проверка результата
К этому документу прилагается тестовый проект, в котором используются некоторые описанные трюки и советы (но не все). В проекте включена оптимизация по размеру кода –Os.
Что делает эта программа? Микроконтроллер использует один канал АЦП чтобы оцифровывать напряжение на входе, полученный результат он отравляет по USART`у каждые пять секунд. Если результат АЦП выходит за диапазон, то в течении 30 секунд посылается сигнал аварии и устройство переходит в режим ошибки.
Размер кода и его быстродействие до и после оптимизации приведены в таблице 5-1.
Таблица 5-1. Результаты оптимизации тестового проекта.

* один цикл - 5 выборок АЦП и одна USART передача
6. Заключение
В этом документе мы перечислили некоторые советы и трюки, позволяющие увеличить эффективность Си кода. Спасибо современным компиляторам, они достаточно умны и применяют различные оптимизации автоматически. Однако ни один компилятор не знает код лучше разработчика, поэтому важно создавать хороших код.
Как показано в примерах, оптимизация одного аспекта может ухудшить другой. Основываясь на своих требованиях, мы должны находить баланс между размером кода и скоростью его выполнения.
Несмотря на то, что у нас есть эти советы и рекомендации по оптимизации Си кода, для их лучшего использования требуется хорошее понимание принципов работы микроконтроллера и компилятора. И, безусловно, существуют и другие методы оптимизации кода в различных случаях.
Ссылки
Atmel AVR4027: Tips and Tricks to Optimize Your C Code for 8-bit AVR MicrocontrollersAVR4027: Трюки и советы по оптимизации Си кода для 8-и разрядных AVR микроконтроллеров. Ч.1
Проект к статье - avr4027.zip
Вольный перевод - ChipEnable.Ru
Comments
Логический оператор И:
Code:
void Bar(uint8_t a, uint8_t b){if(a && b){
PORTB = 0;
PORTA = 0;
}
}
Code:
138: 88 23 and r24, r2413a: 21 f0 breq .+8
13c: 66 23 and r22, r22
13e: 11 f0 breq .+4
140: 18 ba out 0x18, r1
142: 1b ba out 0x1b, r1
144: 08 95 ret
Побитовый оператор И:
Code:
void Bar(uint8_t a, uint8_t b){if(a & b){
PORTB = 0;
PORTA = 0;
}
}
Code:
138: 68 23 and r22, r2413a: 11 f0 breq .+4
13c: 18 ba out 0x18, r1
13e: 1b ba out 0x1b, r1
140: 08 95 ret
В данном случае разница в 4 байта кода и 0-3 такта времени.
Только надо учитывать, что такая оптимизация не всегда применима и выгодна. В данном случае a и b должны быть нормализованным и - 0 или 1.
Еще логический оператор ленивый, он не вычисляет b если a ложно.
Во-первых, чтобы эффективно использовать возможность Си компилировать один и тот же исходник для разных архитектур для большинства переменных (а для временных - вообще для всех) нужно использовать типы uintXX_fast_t (в конкретно этом примере надо использовать тип uint8_fast_t). Для AVR разницы не будет, а вот при использовании этого же кода на 16- или 32-битном процессоре разница уже будет ощутима.
Опечатки: 4.2 "получается при использование", 4.4 - "мы может разделить"
RSS feed for comments to this post